Узнайте, как построить надёжный план аварийного восстановления (DRP) в 2026 году. В материале: целевые метрики RTO/RPO, выбор между холодным, тёплым и облачным резервом, автоматизация восстановления с помощью ИИ и чек-лист для самопроверки вашей IT-инфраструктуры.
Ваш дата-центр умер. Через 3 часа придут с вопросами. Где ваш DR-план?
Представьте: суббота, 2 часа ночи. Система мониторинга взорвалась алертами. Ваш основной кластер недоступен. Через 3 часа после начала простоя топ-менеджмент начнёт задавать неудобные вопросы. Через 6 часов вы потеряете первые миллионы. Через 48 часов — ключевых клиентов.
Disaster recovery (DR) — это не «страшный сон системного администратора», а чёткий план выживания бизнеса. В отличие от простого бэкапа, DR отвечает на вопросы: «Кто, что и в какой последовательности делает, когда всё горит?»
📊 Факт 2026 года: По оценкам аналитиков, компания, пережившая крупный инцидент без работающего DR-плана, в 70% случаев закрывается в течение 2 лет.
Руководство recovery — пошаговый рецепт создания плана, который реально сработает, с примерами, чек-листами и конкретными цифрами.
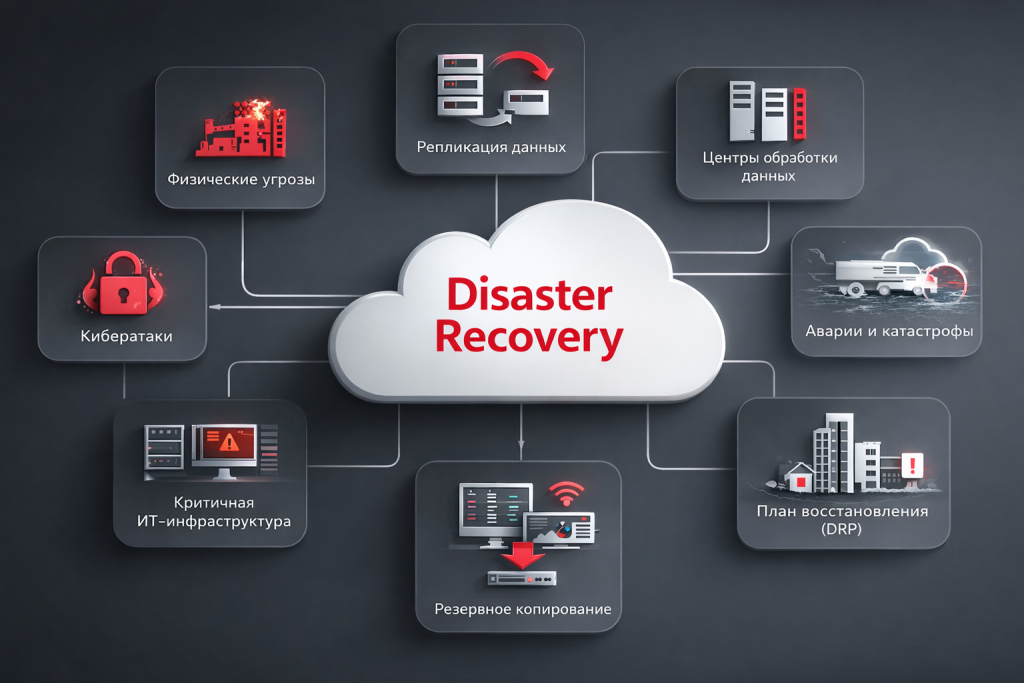
1. Что такое disaster recovery и какие катастрофы он предотвращает?
Disaster recovery — это комплексный подход к восстановлению IT‑инфраструктуры и бизнес‑процессов после инцидента: кибератаки, стихийного бедствия, сбоя оборудования или человеческой ошибки. В отличие от простого резервного копирования, DR охватывает весь цикл: от обнаружения инцидента до полного восстановления работы.
Примеры катастроф, требующих DR:
- 🔒 Кибератаки (программы‑вымогатели, DDoS). Подробнее о защите от шифровальщиков →
- 🌊 Стихийные бедствия (наводнения, пожары, землетрясения).
- 💥 Технические сбои (отказ серверов, сетей, СХД).
- 👤 Человеческий фактор (случайное удаление данных, ошибки конфигурации).
2. Цена вопроса: сколько стоит отсутствие плана
Многие думают: «Мы маленькие, нас не тронет». Но простой в 2026 году — это всегда деньги. Отсутствие плана восстановления влечёт за собой:
- 💰 Финансовые потери: простои, штрафы, затраты на экстренное восстановление.
- 📉 Репутационный ущерб: потеря доверия клиентов и партнёров.
- ⚖️ Юридические риски: несоблюдение нормативов по защите данных (GDPR, ФЗ‑152).
- 🏆 Утрату конкурентных преимуществ: конкуренты могут перехватить долю рынка.
📈 Как растут потери с каждым часом простоя
На примере интернет-магазина с оборотом 1 000 000 руб. в день
Вывод: Каждый час простоя обходится всё дороже — не только из-за выручки, но и из-за штрафов и уходящих клиентов. Хороший DR-план окупается уже при первом серьёзном сбое.

Давайте посчитаем на примере интернет-магазина
Исходные данные: Интернет-магазин с оборотом 1 000 000 руб. в день (пик — выходные).
- ⏱️ Час простоя в рабочее время стоит ≈ 125 000 руб. (1 млн / 8 ч).
- ⏱️ Простой на 6 часов (например, сбой утром в пятницу) = потеря 750 000 руб. выручки.
- 📄 Штрафы от платёжных систем за недоступность (например, 30 000 руб.).
- 👥 Репутационный ущерб: 20% клиентов могут уйти к конкуренту.
Итого один инцидент может стоить более 1 млн руб. + потеря доли рынка.
❓ А теперь вопрос: сколько стоит разработка DR-плана для вашего магазина? Часто это меньше 5% от потенциальных потерь.
3. Руководство recovery: 6 шагов к DR-плану, который реально сработает
Мы не будем писать теорию. Вот алгоритм из шести конкретных шагов.
Шаг 1. Узнайте свои RTO и RPO (это святое)
- RTO (Recovery Time Objective) — на сколько максимально можно остановить сервис? Для онлайн-кассы — 5 минут. Для бухгалтерского архива — 24 часа.
- RPO (Recovery Point Objective) — сколько данных можно потерять? Для базы заказов — 0 секунд (только синхронная репликация). Для резервной копии файлов — 1 час.
Сравнение требований к RTO и RPO для разных типов инцидентов
| Тип инцидента | Рекомендуемый RTO | Рекомендуемый RPO |
|---|---|---|
| Отказ интернет-магазина в час пик | до 15 минут | 0 секунд |
| Сбой внутренней CRM | до 4 часов | до 1 часа |
| Потеря архива документов | до 24 часов | до 12 часов |
| Тестовая среда разработки | до 48 часов | до 24 часов |
Шаг 2. Сделайте инвентаризацию и приоритеты
Выпишите все системы (CRM, 1С, сайт, почта). Разделите на три категории:
- Критичные (без них бизнес умирает за 1 час) — восстанавливаем первыми.
- Важные (простой до 3 суток терпим).
- Второстепенные (можно подождать неделю).
Шаг 3. Выберите площадку для резервирования
Типы альтернативных площадок: холодные, тёплые, горячие резервные центры, облачные решения (DRaaS).
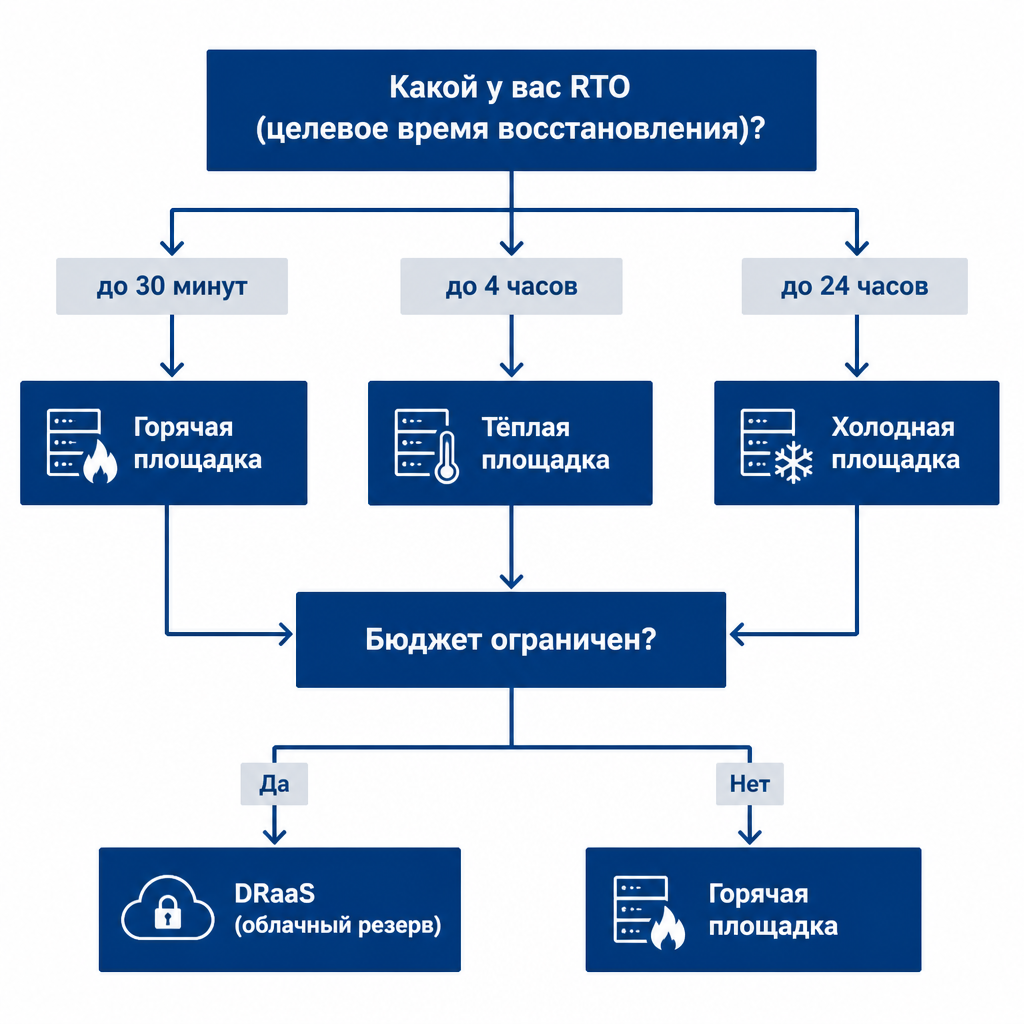
Сравнение типов резервных площадок
Совет 2026 года: Облачные решения (DRaaS) стали стандартом для среднего бизнеса. Вы платите только за аренду «полки» под конфигурацию и активируете мощности при сбое.
Шаг 4. Напишите процедуры для каждого сценария
Не «если что-то случится», а конкретно:
- Сценарий А: Пожар в основном ЦОД → активировать горячую площадку, переключить DNS.
- Сценарий Б: Ошибка админа с данными → откат на инкрементный бэкап за 2 часа до инцидента.
- Сценарий В: Атака шифровальщика → изолировать заражённые сегменты, восстановить из offline-бэкапов.
Шаг 5. Назначьте роли и план коммуникации
За каждым действием должен стоять живой человек с телефоном. Это и есть роли и ответственности:
- DR-лидер: принимает решение на активацию плана.
- Техническая группа (2-3 человека): выполняют восстановление.
- Группа коммуникации: готовят тексты для клиентов, партнёров, регуляторов — ваш план коммуникации.
Шаг 6. Документирование и хранение плана
План в файле на рабочем столе админа — это не план. Храните копии:
- В распечатанном виде (в сейфе у DR-лидера).
- На защищённом облачном диске.
- В системе управления конфигурациями (например, Git).
Как тестировать DR-план: 3 уровня проверки
- Tabletop (столовые учения): команда обсуждает сценарий сбоя и свои действия, без воздействия на продакшн.
- Partial failover (частичное переключение): переключение только части систем на резервный контур.
- Full failover (полное переключение): полное переключение всех сервисов на резерв.
Рекомендация: проводите partial failover ежеквартально, full failover — раз в полгода.
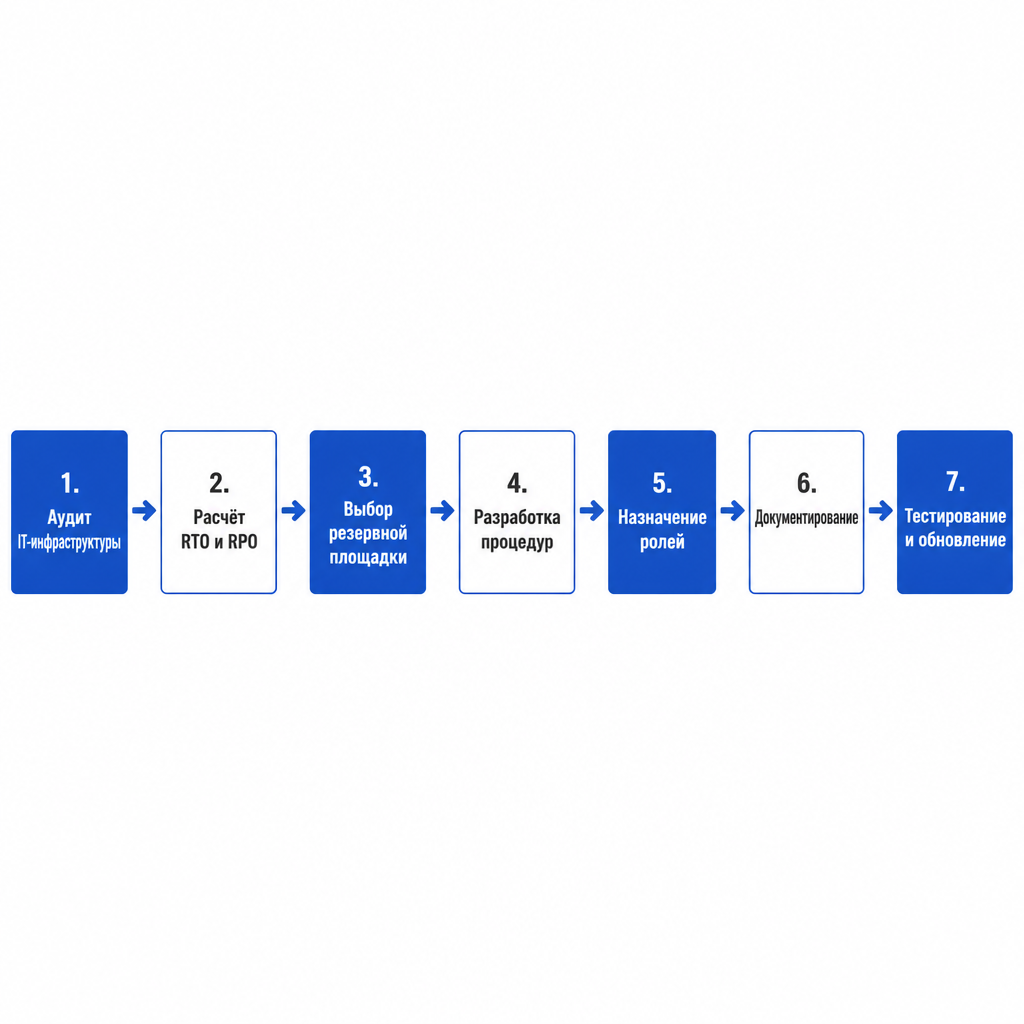
Полный цикл создания DR-плана (дополнительные шаги):
- Аудит IT‑инфраструктуры: инвентаризация систем, оценка уязвимостей.
- Оценка рисков: анализ вероятности и последствий различных инцидентов.
- Приоритизация бизнес‑процессов: определение критических систем.
- Выбор технологий: локальные решения, облако, гибридные схемы.
- Разработка процедур: пошаговые инструкции для разных сценариев.
- Документирование: создание единого регламента DR‑плана.
- Обучение сотрудников: тренинги и симуляции инцидентов.
- Тестирование и обновление: регулярные учения и актуализация плана.
4. Технологии 2026 года: ИИ, облака и автоматизация
Старые методы (скрипты на cron, копии на внешний диск) уже не проходят аудит. В 2026 году DR‑планы активно используют:
- ☁️ Облачные решения (IaaS, DRaaS): мгновенное развёртывание резервных мощностей.
- 🤖 Автоматизацию восстановления: скрипты и оркестраторы для быстрого возврата к работе.
- 🧠 ИИ для прогнозирования рисков: анализ аномалий и превентивное реагирование.
- 📡 Интеграцию с системами мониторинга: автоматическое обнаружение инцидентов.
Особый вызов — микросервисная архитектура и распределённые данные. Сбой в одном узле может вызвать каскад проблем.
Чтобы минимизировать риски, современные DR-планы включают:
- Идемпотентность — повторная обработка запроса не изменяет результат.
- Версионирование (versioning) — хранение версий данных и схем.
- Event sourcing — фиксация всех событий, изменяющих состояние системы.
5. Живые кейсы: как DR спас бизнес
- 🛒 Ритейл: восстановление онлайн‑магазина после DDoS‑атаки за 2 часа.
- 🏦 Финансы: бесперебойная работа банка при отключении дата‑центра.
- 🏥 Здравоохранение: быстрый доступ к электронным медкартам после сбоя.
🏆 Кейс X-Com: как мы восстановили производственную компанию за 4 часа
Ситуация: В пятницу вечером вирус-шифровальщик зашифровал все файлы на сервере 1С и файловом хранилище клиента.
Что сделали: У клиента был настроен наш облачный DRaaS-контур с еженедельной полной копией и ежедневными инкрементальными бэкапами.
- ⏱️ За 30 минут — запустили процесс восстановления.
- ⏱️ За 4 часа — 1С, файловое хранилище и почта снова работали.
- 📉 Потери данных: 0 (RPO = 0). Простой: 4 часа (RTO = 4 ч).
Результат: Компания не потеряла ни одного документа и открылась в понедельник как ни в чём не бывало.
6. Чек-лист: проверьте готовность вашего DR за 15 минут
Ответьте «да» или «нет» на эти вопросы. Если хотя бы 3 ответа «нет» — у вас нет DR-плана.
- ⬜ У нас письменно задокументированы RTO и RPO для каждого критического сервиса.
- ⬜ Мы знаем точное местонахождение трёх копий плана восстановления.
- ⬜ В течение последних 6 месяцев мы реально восстанавливали сервис из бэкапа.
- ⬜ У нас есть утверждённый бюджет на аренду резервной площадки (или DRaaS).
- ⬜ Назначены конкретные люди с запасными номерами телефонов для ролей.
- ⬜ Процедура восстановления расписана по шагам.
- ⬜ Мы знаем, сколько денег потеряем за 1 час простоя самого важного сервиса.
Результат:
✅ 7 «да» — вы редкий молодец.
⚠️ 4–6 «да» — хорошая основа, но есть слабые места.
❌ 0–3 «да» — у вас нет работающего DR-плана.
7. Типичные ошибки, которые убивают DR-план (даже хороший)
X-Com работает на рынке с 1994 года — более 30 лет. Мы видели сотни инцидентов.
- «Священная корова» — ни разу не тестировали.
- «Секрет Полишинеля» — план знает один человек.
- «Бумажный тигр» — RTO и RPO не соответствуют бизнесу.
- «Соло на нервах» — нет автоматизации.
- «Мёртвая душа» — не обновляли план.
❓ Часто задаваемые вопросы о руководстве recovery
1. Что такое RTO и RPO в руководстве recovery?
RTO (Recovery Time Objective) — целевое время восстановления сервиса. RPO (Recovery Point Objective) — допустимые потери данных.
2. Чем руководство recovery отличается от обычного бэкапа?
Бэкап — это копия данных. Руководство recovery — полный план действий при катастрофе.
3. Как часто нужно тестировать руководство recovery?
Partial failover — ежеквартально, full failover — раз в полгода.
4. Какие типы резервных площадок существуют?
Холодная, тёплая, горячая, облачная DRaaS. Подробнее — в статье выше.
5. Сколько стоит разработка руководства recovery?
Часто менее 5% от потенциальных потерь. Запросить консультацию →
Заключение: инвестируйте в DR, пока не поздно
Disaster recovery в 2026 году — это страховка существования бизнеса. Начните с малого:
- Скачайте чек-лист.
- Проговорите сценарии с коллегами.
- Зафиксируйте ответы на бумаге.
Почему X-Com?
Группа компаний X-Com работает на российском ИТ-рынке с 1994 года — более 30 лет.
- ✅ Системная интеграция, ИТ-сервис, поставка оборудования — под ключ.
- ✅ Клиенты — компании всех отраслей, госорганизации.
- ✅ Десятки успешных проектов, включая Росатом, Ростелеком, Почту России.
- ✅ Сертификат ISO 9001:2011.
❗ Хотите, чтобы мы провели аудит вашей IT-инфраструктуры?
Наши инженеры за 3 дня выявят скрытые точки отказа и предложат 2-3 варианта DR-плана.
📩 Запросить консультацию